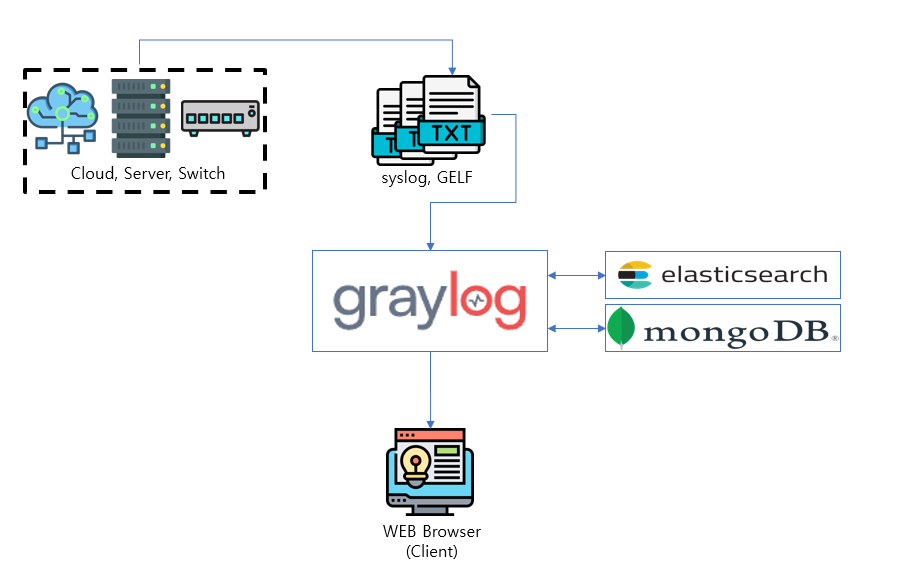
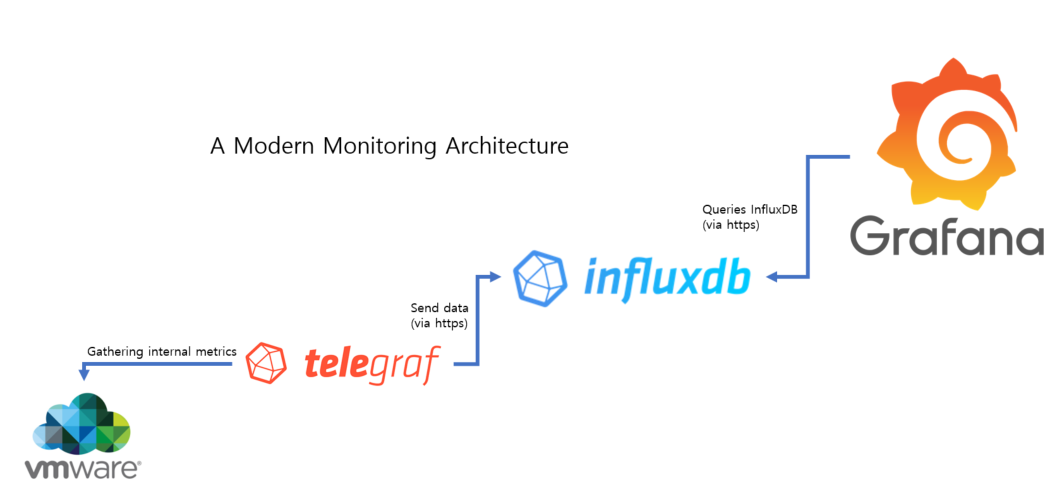
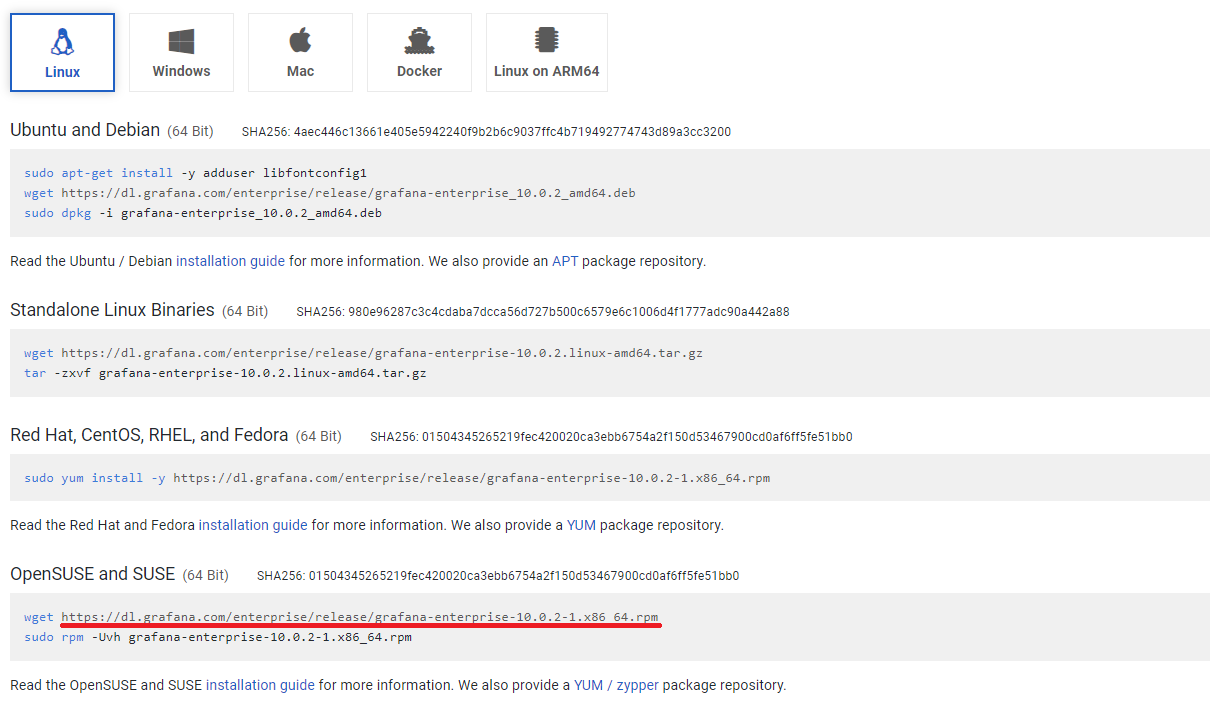
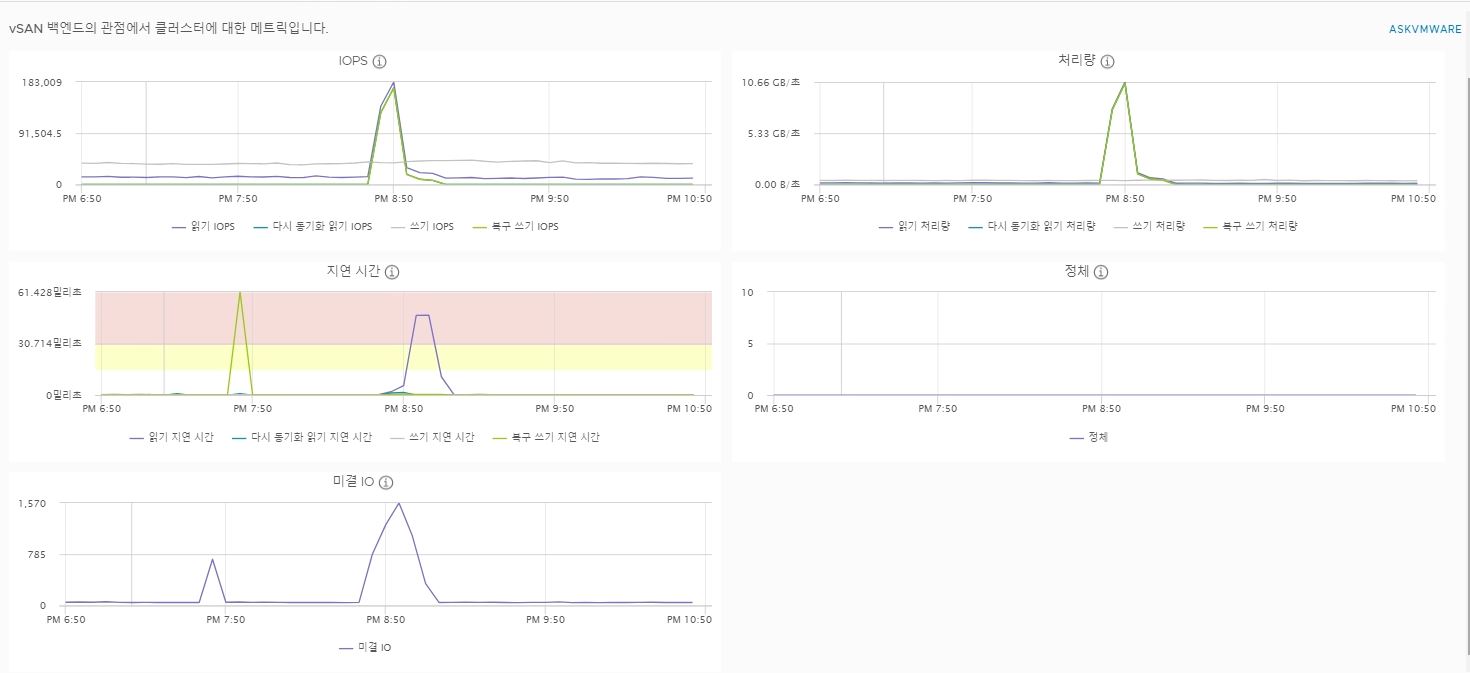
Show configuration
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl all show config
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl all show config
Controller status
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl all show status
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl all show status
Show detailed controller information for all controllers
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl all show detail
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl all show detail
Show detailed controller information for controller in slot 0
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 show detail
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 show detail
Rescan for New Devices
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli rescan
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli rescan
Physical disk status
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 pd all show status
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 pd all show status
Show detailed physical disk information
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 pd all show detail
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 pd all show detail
Logical disk status
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 ld all show status
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 ld all show status
View Detailed Logical Drive Status
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 ld 2 show
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 ld 2 show
Create New RAID 0 Logical Drive
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 create type=ld drives=1I:1:2 raid=0
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 create type=ld drives=1I:1:2 raid=0
Create New RAID 1 Logical Drive
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 create type=ld drives=1I:1:1,1I:1:2 raid=1
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 create type=ld drives=1I:1:1,1I:1:2 raid=1
Create New RAID 5 Logical Drive
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 create type=ld drives=1I:1:1,1I:1:2,2I:1:6,2I:1:7,2I:1:8 raid=5
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 create type=ld drives=1I:1:1,1I:1:2,2I:1:6,2I:1:7,2I:1:8 raid=5
Delete Logical Drive
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 ld 2 delete
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 ld 2 delete
Add New Physical Drive to Logical Volume
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 ld 2 add drives=2I:1:6,2I:1:7
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 ld 2 add drives=2I:1:6,2I:1:7
Add Spare Disks
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 array all add spares=2I:1:6,2I:1:7
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 array all add spares=2I:1:6,2I:1:7
Enable Drive Write Cache
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 modify dwc=enable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 modify dwc=enable
Disable Drive Write Cache
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 modify dwc=disable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 modify dwc=disable
Erase Physical Drive
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 pd 2I:1:6 modify erase
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 pd 2I:1:6 modify erase
Turn on Blink Physical Disk LED
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 ld 2 modify led=on
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 ld 2 modify led=on
Turn off Blink Physical Disk LED
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 ld 2 modify led=off
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 ld 2 modify led=off
Modify smart array cache read and write ratio (cacheratio=readratio/writeratio)
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 modify cacheratio=100/0
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 modify cacheratio=100/0
Enable smart array write cache when no battery is present (No-Battery Write Cache option)
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 modify nbwc=enable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 modify nbwc=enable
Disable smart array cache for certain Logical Volume
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 logicaldrive 1 modify arrayaccelerator=disable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 logicaldrive 1 modify arrayaccelerator=disable
Enable smart array cache for certain Logical Volume
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 logicaldrive 1 modify arrayaccelerator=enable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 logicaldrive 1 modify arrayaccelerator=enable
Enable SSD Smart Path
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 array a modify ssdsmartpath=enable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 array a modify ssdsmartpath=enable
Disable SSD Smart Path
ESXi 5.5 -> /opt/hp/hpssacli/bin/hpssacli ctrl slot=0 array a modify ssdsmartpath=disable
ESXi 6.5 -> /opt/smartstorageadmin/ssacli/bin/ssacli ctrl slot=0 array a modify ssdsmartpath=disable
BIOS Information
vish
get /hardware/bios/biosInfo
출처 : kallesplayground.wordpress.com/useful-stuff/hp-smart-array-cli-commands-under-esxi/